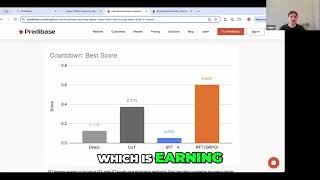
Page Snapshot: Check out the NVIDIA Inception Program for Startups here: ▻Full article and references: ... Get the guide to GAI, learn more → Learn more about the technology → Join Cedric ...
What Is Reinforcement Fine Tuning Rft Supervised Vs Rl Llm Re Training - Outfit Before You Continue
This expanded guide maps What Is Reinforcement Fine Tuning Rft Supervised Vs Rl Llm Re Training through topic clusters, supporting snippets, intent signals, and verification reminders with enough variation for broader AGC-style topic coverage.
In addition, this page also connects What Is Reinforcement Fine Tuning Rft Supervised Vs Rl Llm Re Training with for broader topic coverage.
Outfit Before You Continue
Get the guide to GAI, learn more → Learn more about the technology → Join Cedric ... Organizations struggle to customize AI models for complex tasks due to the extensive human annotation required for traditional ...
Fashion Knowledge Map
A clean overview helps readers understand What Is Reinforcement Fine Tuning Rft Supervised Vs Rl Llm Re Training before moving into details, examples, or connected topics.
Fashion Relevant Factors
This section highlights the practical pieces readers may want before opening a more specific related page.
Search Background
Context matters because What Is Reinforcement Fine Tuning Rft Supervised Vs Rl Llm Re Training can connect to nearby topics, related searches, and different reader intents.
Main details to review
- Check out the NVIDIA Inception Program for Startups here: ▻Full article and references: ...
- Organizations struggle to customize AI models for complex tasks due to the extensive human annotation required for traditional ...
- Get the guide to GAI, learn more → Learn more about the technology → Join Cedric ...
Why this overview helps
A structured page helps by giving readers a less scattered reference for What Is Reinforcement Fine Tuning Rft Supervised Vs Rl Llm Re Training while keeping the topic easy to scan.
Reader Questions
Why do people search for What Is Reinforcement Fine Tuning Rft Supervised Vs Rl Llm Re Training?
People often search for What Is Reinforcement Fine Tuning Rft Supervised Vs Rl Llm Re Training to understand the basics, compare related options, or find a clearer path to more specific information.
Is this page a final source?
No. It is best used as a quick reference and discovery page before checking stronger or official sources.
What is the safest way to use What Is Reinforcement Fine Tuning Rft Supervised Vs Rl Llm Re Training information?
Use it as general context first, then verify important points with official, primary, or more specific sources when accuracy matters.