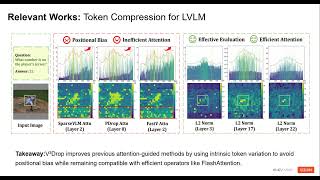
Useful Context: Hyun Lee, Hyemin Jeong, Yejin Kim, Hyungwook Choi, Hyunsoo Cho, Soo Kyung Kim, Joonseok Lee. [CVPR 2026] Aligning What Vision-Language Models See and Perceive with Adaptive Information Flow
Cvpr 2026 Blink Dynamic Visual Token Resolution For Enhanced Multimodal Understanding - Search Overview for Readers
This expanded guide maps Cvpr 2026 Blink Dynamic Visual Token Resolution For Enhanced Multimodal Understanding through topic clusters, supporting snippets, intent signals, and verification reminders so the page can feel more natural across many search queries.
In addition, this page also connects Cvpr 2026 Blink Dynamic Visual Token Resolution For Enhanced Multimodal Understanding with for broader topic coverage.
Search Overview for Readers
[CVPR 2026] Aligning What Vision-Language Models See and Perceive with Adaptive Information Flow Hyun Lee, Hyemin Jeong, Yejin Kim, Hyungwook Choi, Hyunsoo Cho, Soo Kyung Kim, Joonseok Lee.
Topic Background
This part keeps Cvpr 2026 Blink Dynamic Visual Token Resolution For Enhanced Multimodal Understanding connected to practical references instead of leaving it as a single isolated phrase.
Research Tips for Readers
Before relying on any single result, compare related pages and verify important facts from stronger sources.
Useful Signals
Important details can vary by source, so this page groups the most readable points into a scannable format.
Key points worth scanning
- [CVPR 2026] Aligning What Vision-Language Models See and Perceive with Adaptive Information Flow
- Hyun Lee, Hyemin Jeong, Yejin Kim, Hyungwook Choi, Hyunsoo Cho, Soo Kyung Kim, Joonseok Lee.
How readers can use this page
This format works because it offers comparison ideas for Cvpr 2026 Blink Dynamic Visual Token Resolution For Enhanced Multimodal Understanding while keeping the topic easy to scan.
Helpful Questions
How does Cvpr 2026 Blink Dynamic Visual Token Resolution For Enhanced Multimodal Understanding connect to outfit?
Cvpr 2026 Blink Dynamic Visual Token Resolution For Enhanced Multimodal Understanding can connect to outfit when readers need context, examples, comparisons, or practical next steps inside the same topic area.
How does Cvpr 2026 Blink Dynamic Visual Token Resolution For Enhanced Multimodal Understanding connect to trend?
Cvpr 2026 Blink Dynamic Visual Token Resolution For Enhanced Multimodal Understanding can connect to trend when readers need context, examples, comparisons, or practical next steps inside the same topic area.
What should be avoided when researching Cvpr 2026 Blink Dynamic Visual Token Resolution For Enhanced Multimodal Understanding?
Avoid treating one short snippet as complete, especially when the topic involves money, health, law, schedules, or current details.


![[CVPR 2026] Aligning What Vision-Language Models See and Perceive with Adaptive Information Flow](https://i.ytimg.com/vi/jQ0tggtLP7I/mqdefault.jpg)
![[CVPR 2026]](https://i.ytimg.com/vi/YYRFWBM9x-g/mqdefault.jpg)
![[CVPR 2026] VAD-GS](https://i.ytimg.com/vi/vq7EhjpogY0/mqdefault.jpg)
![[CVPR 2026] A More Word-like Image Tokenization for MLLMs](https://i.ytimg.com/vi/ILGGwINIWD0/mqdefault.jpg)

![[CVPR 2026] Multimodal Continual Instruction Tuning with Dynamic Gradient Guidance](https://i.ytimg.com/vi/JzPtD6xmd6A/mqdefault.jpg)
![[CVPR 2026] MetaCompress: Rethinking Token Reduction for Large Vision-Language Models](https://i.ytimg.com/vi/o30V0TPycFk/mqdefault.jpg)